Parallel Transducing Context Shootout: |>> vs =>>
Welcome to the parallel transducer context shootout!
Here you'll find comparative benchmarks between |>> ('pipeline-thread-last') and =>> ('fold-thread-last').
You can learn more about these injest macros in the readme.
In this comparative analysis, we explore a few different scenarios on both a 4 core machine and a 16 core machine.
First, let's define some testing functions:
(require '[clojure.edn :as edn])
(defn work-1000 [work-fn]
(range (last (repeatedly 1000 work-fn))))
(defn x>>work [input]
(work-1000
(fn []
(x>> input
(map inc)
(filter odd?)
(mapcat #(do [% (dec %)]))
(partition-by #(= 0 (mod % 5)))
(map (partial apply +))
(map (partial + 10))
(map #(do {:temp-value %}))
(map :temp-value)
(filter even?)
(apply +)
str
(take 3)
(apply str)
edn/read-string))))
;; and one extra macro for returning a value for the number of seconds passed:
(defmacro time-val [& body]
`(x>> (time ~@body)
with-out-str
(drop 15)
reverse
(drop 8)
reverse
(apply str)
edn/read-string
(* 0.001)))
You may recognize those test functions from the readme. Now let's exercise them:
(dotimes [i 50]
(println
(=>> (range 100)
(repeat i)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
time-val)))
;; and
(dotimes [i 50]
(println
(|>> (range 100)
(repeat i)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
(map x>>work)
time-val)))
With 4 cores:

With 16 cores:

In the above example, all we're doing is increasing sequence size while keeping the workload the same, so |>> and =>> are tracking pretty closely to one another.
If we want to measure different workloads, we'll need to get a little fancier with our testing functions.
(defn work [n]
(time-val
(->> (range n)
(mapv (fn [_]
(x>> (range n)
(map inc)
(filter odd?)
(mapcat #(do [% (dec %)]))
(partition-by #(= 0 (mod % 5)))
(map (partial apply +))
(map (partial + 10))
(map #(do {:temp-value %}))
(map :temp-value)
(filter even?)
(apply +)))))))
(defn run-|>> [l w]
(|>> (range l)
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))))
(defn run-=>> [l w]
(=>> (range l)
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))))
We start with a work function that becomes increasingly more expensive as n rises. We then define run functions run-|>> and run-=>> that take a sequence length l and a work width w. Each run function exercises the work function 16 times. This way, we can get a sense of how sequence size vs workload size affects performance characteristics.
Let's look at a "medium" sized work load:
(dotimes [n 10]
(println (time-val (last (run-|>> 100 (* n 100))))))
;; and
(dotimes [n 10]
(println (time-val (last (run-=>> 100 (* n 100))))))
Here, we're saying 100 (* n 100) is a sequence 100 elements long, where n increases by 100 on each step. Let's see how they compare.
On 4 cores:

On 16 cores:
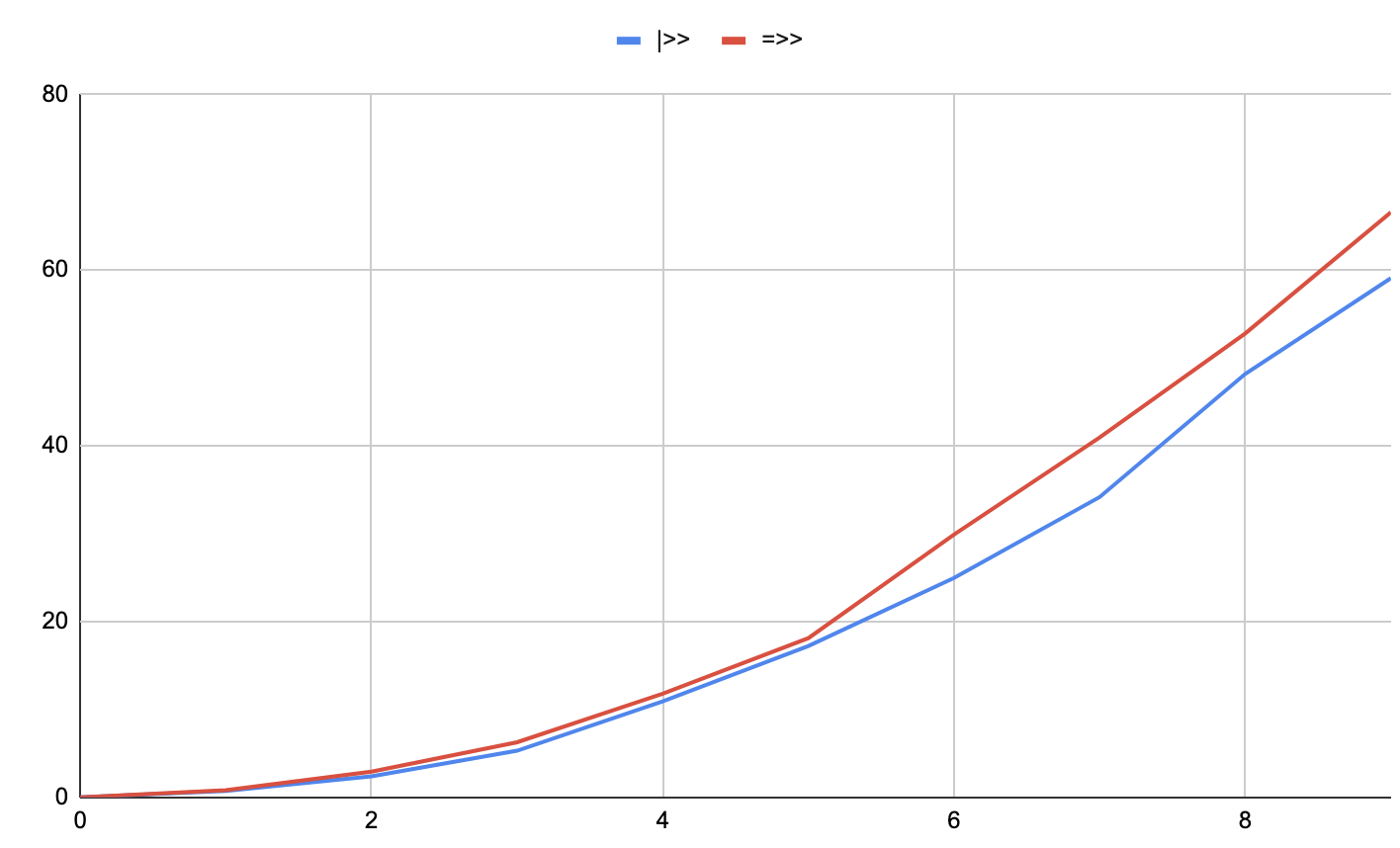
In this example, the |>> pipeline thread does a little better in the high core count scenario. In the low core count scenario, they're almost identical.
Now let's try a small, constant size workload with an increasingly larger sequence:
(dotimes [n 10]
(println (time-val (last (run-|>> (* n 1000) 10)))))
;; and
(dotimes [n 10]
(println (time-val (last (run-=>> (* n 1000) 10)))))
On 4 cores:

On 16 cores:

Much to my surprise, |>> won out with this particular workload on both 4 and 16 cores.
How far can we take that? Let's try it with a really big sequence and a really small workload:
(dotimes [n 10]
(println (time-val (last (run-|>> (* n 10000) 1)))))
;; and
(dotimes [n 10]
(println (time-val (last (run-=>> (* n 10000) 1)))))
On 4 cores:

On 16 cores:

On both core counts, =>> wins out slightly. Here, we can see that |>> starts to fall behind when threads are not optimized for heavy workloads.
What about the opposite scenario? Let's try a small, constant size sequence with an increasingly, extremely large workload per item:
(dotimes [n 4]
(println (time-val (last (run-|>> 10 (* n 1000))))))
;; and
(dotimes [n 4]
(println (time-val (last (run-=>> 10 (* n 1000))))))
We're only doing 4 runs here because the results take a while.
On 4 cores:

On 16 cores:

As you can see, this is where |>> really shines: With super heavy work and a very high core count, pipeline starts to show significant efficiencies.
Given these characteristics, one might ask, "Why not always use |>> then?"
Unfortunately, |>> falls over with extremely large sequences with small, heterogeneous workloads. injest is designed to allow users to mix and match threads with transformation functions that are fully lazy, transducable and/or parallelizable. Under the hood, this sometimes involves passing some results to a sequence operation, then to a pipeline operation, then to a lazy (apply foo) operation, etc. I believe that in these heterogeneous workload scenarios, the thread communications for |>> is causing a traffic jam. Still under investigation though.
For example, let's look at this test scenario:
(dotimes [n 10]
(|>> (range (* n 100000))
(map inc)
(filter odd?)
(mapcat #(do [% (dec %)]))
(partition-by #(= 0 (mod % 5)))
(map (partial apply +))
(map (partial + 10))
(map #(do {:temp-value %}))
(map :temp-value)
(filter even?)
(apply +)
time-val
println))
;; and
(dotimes [n 10]
(=>> (range (* n 100000))
(map inc)
(filter odd?)
(mapcat #(do [% (dec %)]))
(partition-by #(= 0 (mod % 5)))
(map (partial apply +))
(map (partial + 10))
(map #(do {:temp-value %}))
(map :temp-value)
(filter even?)
(apply +)
time-val
println))
On 4 cores:
todo
On 16 cores:
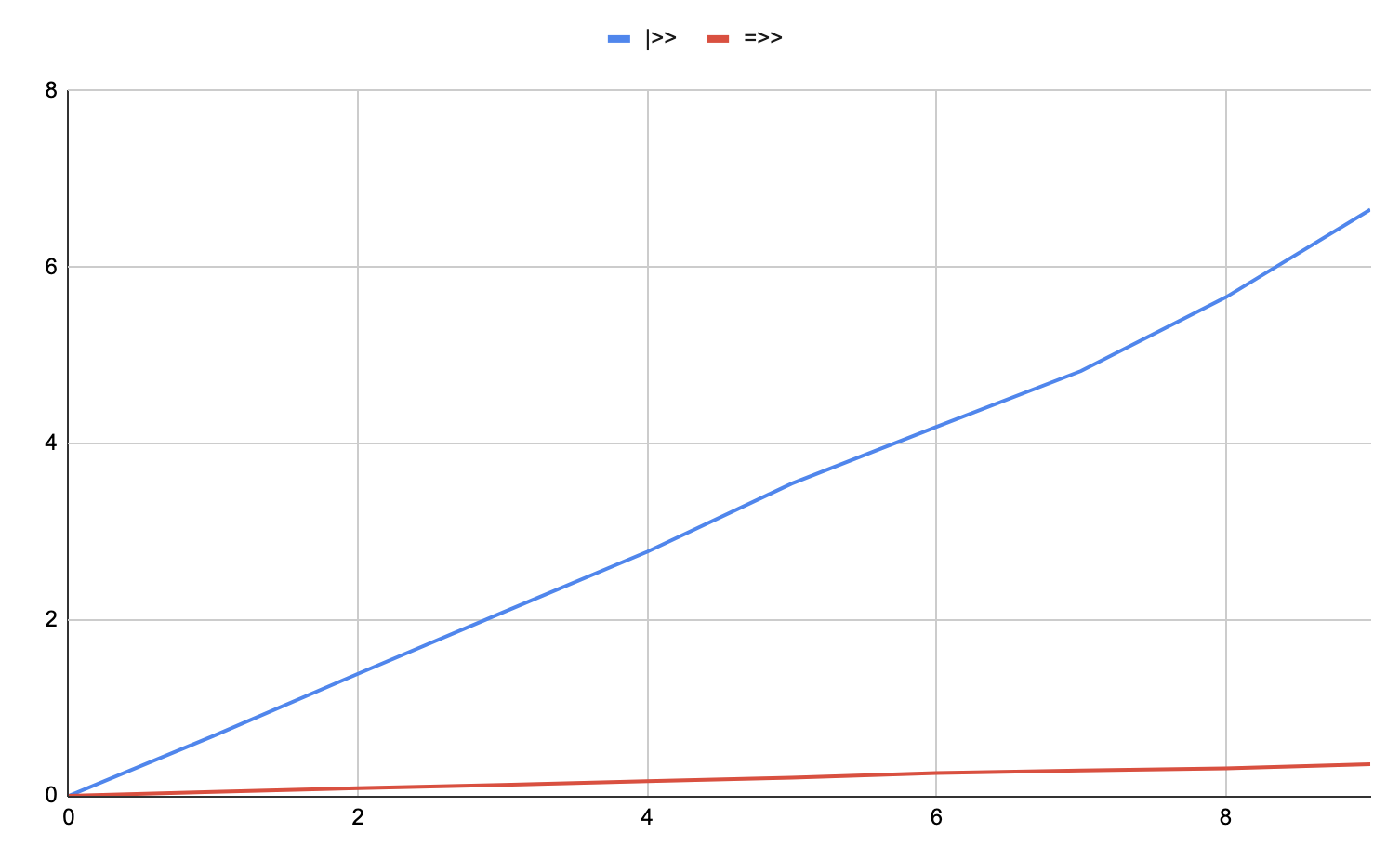
And that issue only compounds as the sequence size rises.
So, let's be honest: at least half of the sequence transformation threads that we usually build with ->> in Clojure are not homogenous, heavily loaded threads. So, if a given thread is only just starting to seem like it could benefit from parallelization, then it's a good chance that |>> will be a footgun for you, while =>> may pay dividends - so in general I recommend reaching for =>> first. However, once your threads' workloads starts to become embarrasingly parallel, then it makes sense to try out |>>, to see if it can get you even farther - especially with more available cores.
I know, you're wondering, what do these tests look like against the single threaded transducing x>> and classical, lazy ->> macros?
Let's add a test case for that:
(defn lazy-work [n]
(time-val
(->> (range n)
(mapv (fn [_]
(->> (range n)
(map inc)
(filter odd?)
(mapcat #(do [% (dec %)]))
(partition-by #(= 0 (mod % 5)))
(map (partial apply +))
(map (partial + 10))
(map #(do {:temp-value %}))
(map :temp-value)
(filter even?)
(apply +)))))))
(defn run-x>> [l w]
(x>> (range l)
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))
(map (fn [_] (work w)))))
(defn run-->> [l w]
(->> (range l)
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))
(map (fn [_] (lazy-work w)))))
Now, looking at our "medium" sized work load above:
(dotimes [n 10]
(println (time-val (last (run-x>> 100 (* n 100))))))
;; and
(dotimes [n 10]
(println (time-val (last (run-->> 100 (* n 100))))))
And adding those to our times, we get:
On 4 cores:

On 16 cores:

As you can see, it would have taken a very long time for the lazy version to ever finish all ten iterations.
Let's see it with the small sequence, large work version:
(dotimes [n 4]
(println (time-val (last (run-x>> 10 (* n 1000))))))
;; and
(dotimes [n 4]
(println (time-val (last (run-->> 10 (* n 1000))))))
On 4 cores:

On 16 cores:

Aha!, We've discovered that =>> is breaking for very small sequences (here 10). But only when it is shorter than the number of cores - in this case, in the 16 core version being greater than the number of items available in the sequence. We'll see if we can optimize this in our parallelism strategy.
Let's see how these comparisons fair in the very large sequence cases:
todo
Now let's see the case of an extremely large sequence with heterogeneous data and work:
On 4 cores:

On 16 cores:

Here we can see that, with this kind of workload, the best we can do is try to keep up with the single threaded transducer version - which the =>> version does a pretty good job of.
Can you improve this documentation?Edit on GitHub
cljdoc is a website building & hosting documentation for Clojure/Script libraries
× close