Liking cljdoc? Tell your friends :D
Architecture & Low Level Design
This chapter outlines how Onyx works on the inside to meet the required properties of a distributed data processing system. This is not a formal proof nor an iron-clad specification for other implementations of Onyx. I will do my best to be transparent about how everything is working under the hood - good and bad. If something doesn’t make sense, keep moving. There are inevitable forward references.
High Level Components
Peer
A Peer is a node in the cluster responsible for processing data. A peer generally refers to a physical machine as its typical to only run one peer per machine.
Virtual Peer
A Virtual Peer refers to a single concurent worker running on a single physical machine. Each virtual peer spawns a small number threads since it uses asynchronous messaging. All virtual peers are equal, whether they are on the same physical machine or not. Virtual peers communicate segments directly to one another, and coordinate strictly via the log in ZooKeeper.
ZooKeeper
Apache ZooKeeper is used as both storage and communication layer. ZooKeeper takes care of things like CAS, consensus, and atomic counting. ZooKeeper watches are at the heart of how Onyx virtual peers detect machine failure.
Aeron
Aeron is the primary messaging transport layer. The transport layer is pluggable, though we don’t support any other transports at this time.
Asynchronous Barrier Snapshotting
Asynchronous Barrier Snapshotting (ABS) provides fault tolerance and exactly once processing by inserting and tracking barriers that flow through the Directed Acyclic Graph (DAG).
Motivation
ABS improves performance by reducing acking overhead present in Onyx 0.9, and allows for exactly once aggregations which do not require message de-duplication. In ABS, consistent state snapshots can be made by tracking and aligning the barriers, and snapshotting state at appropriate points of barrier alignment.
Concepts
Onyx 0.10.0 and above uses the Asynchronous Barrier Snapshotting method described in Lightweight Asynchronous Snapshots for Distributed Dataflows, Carbone et al., and Distributed Snapshots: Determining Global States of Distributed Systems, Chandy, Lamport to ensure fault tolerance and exactly once processing of data (not exactly once side effects!).
Every job is assigned a coordinator peer, that notifies input peers of when they should inject a barrier into their datastream (generally every n seconds). These barriers are tracked and aligned throughout the job, with the tasks performing snapshots of their state every time a barrier is aligned from all of its input channels.
Concepts:
-
Barrier: a message injected into the data stream, containing the epoch id of the barrier.
-
Epoch: the id of the barrier, re-starting from 0 whenever the cluster has performed a reallocation.
-
Coordinator - a process that injects a barrier into the data stream on a schedule.
-
Barrier Alignment: occurs when barriers with a particular id have been received from all input channels on a peer.
-
Snapshot: Peer state that can be stored whenever a barrier alignment has occurred.
-
Channel: Network messaging channel. Channel may become blocked waiting for channel alignment.
ABS Execution Example
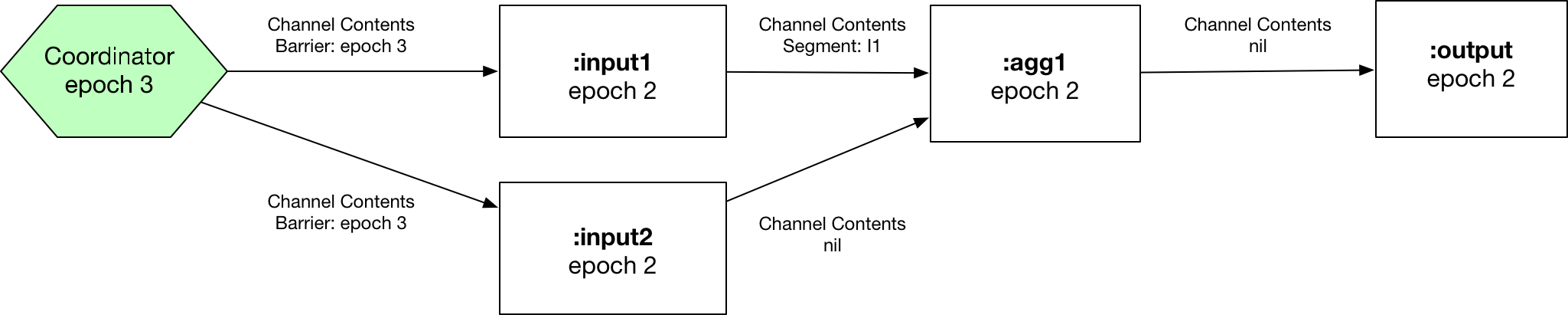
Step 1: Coordinator peer emits barrier with epoch 3 after the coordinator period passes.
Step 2: :input1 peer synchronizes on epoch 3, snapshots state to durable storage, and re-emits the barrier.
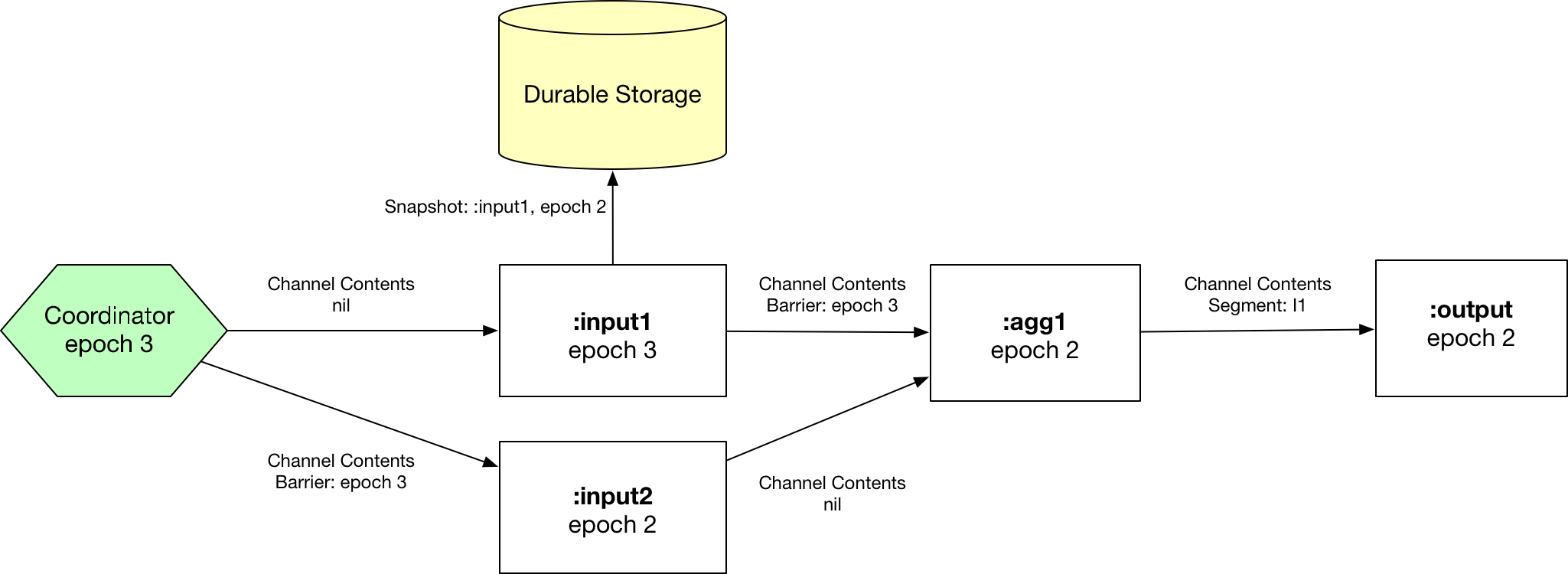
Step 3: :input2 peer synchronizes on epoch 3, snapshots state to durable storage, and re-emits the barrier. :agg1 reads barrier with epoch 3 from :input1, blocks the channel.
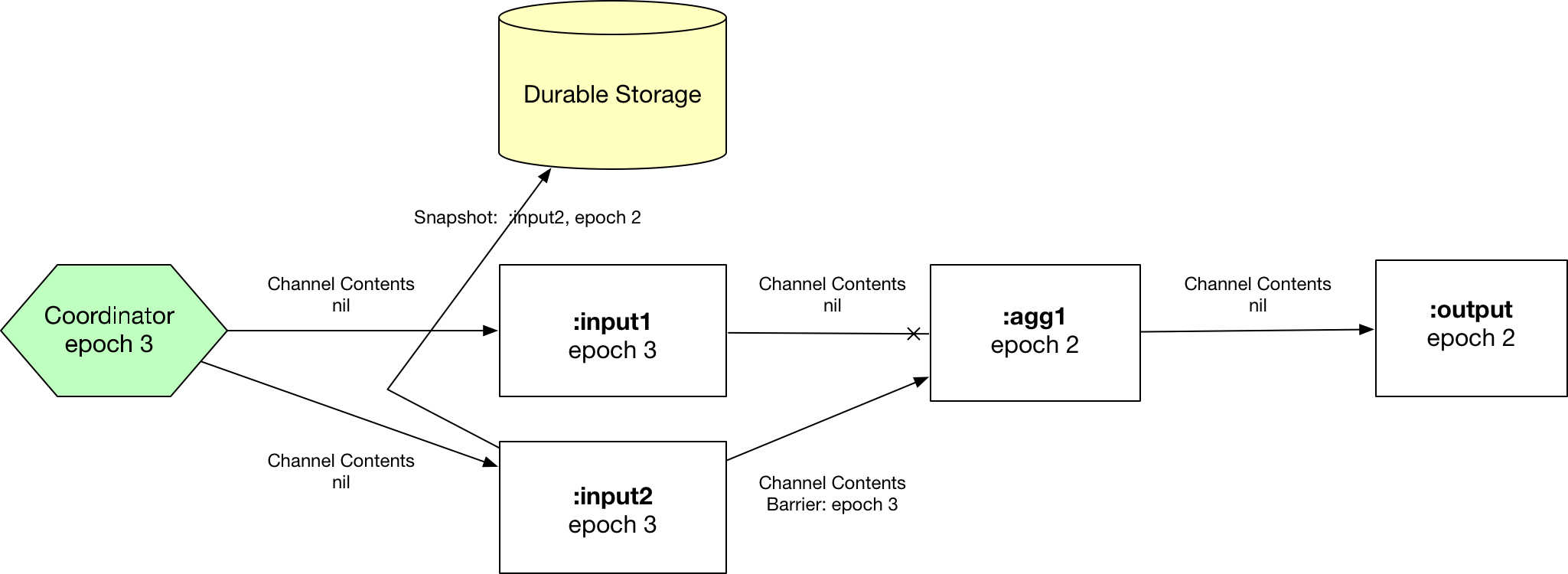
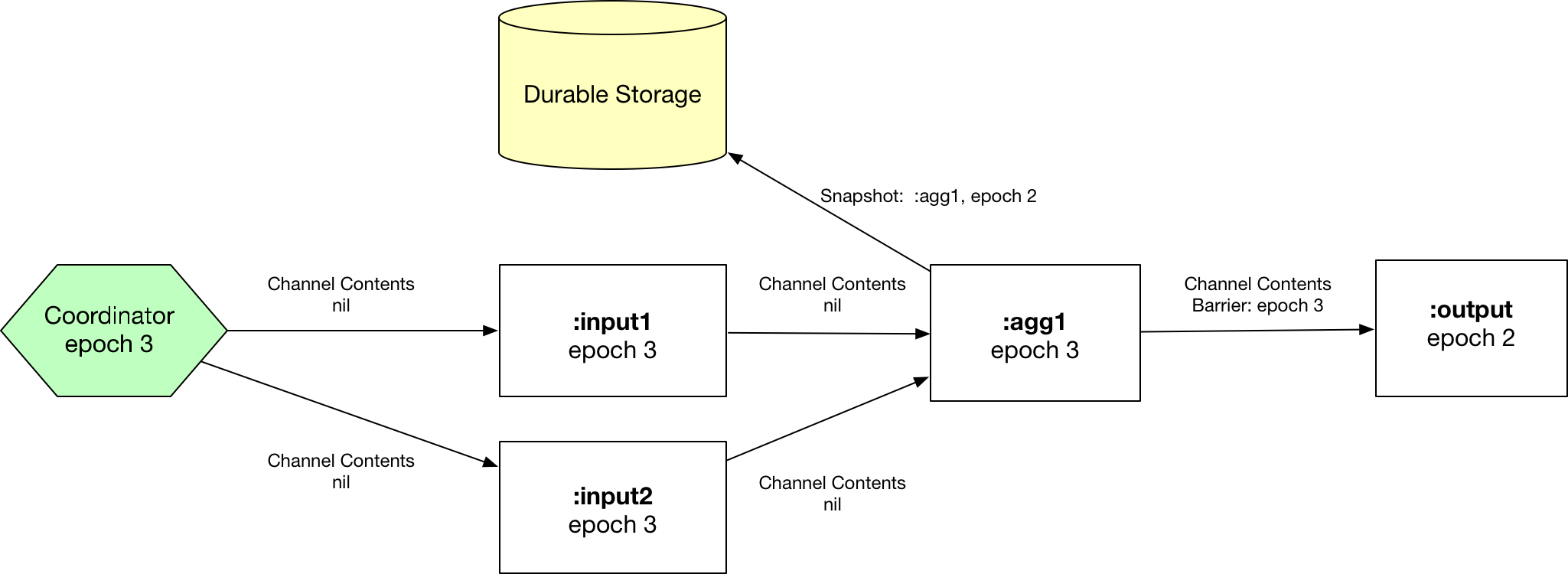
Step 4: :agg1 synchronizes on epoch 3, snapshots state to durable storage, and re-emits the barrier to :output.
Phases of Execution
A batch of segments runs through the phases and execution states described here in the cheat sheet.
The Log
This design centers around a totally ordered sequence of commands using
a log structure. The log acts as an immutable history and arbiter. It’s
maintained through ZooKeeper using a directory of persistent, sequential
znodes. Virtual peers act as processes that consume from the log. At the
time a peer starts up, it initializes its local replica to the "empty
state". Log entries represent deterministic, idempotent functions to be
applied to the local replica. The peer plays the log from the beginning,
applying each log entry to its local replica. The local replica is
transformed from one value to another. As a reaction to each replica
transformation, the peer may send more commands to the tail of the log.
Peers may play the log at any rate. After each peer has played k log
entries, all peers at time k will have exactly the same local
replica. Peers store everything in memory - so if a peer fails, it
simply reboots from scratch with a new identifier and plays the log
forward from the beginning. Since it has a new identifier, it has no
association to the commands it previously issued; this prevents live
lock issues.
The Inbox and Outbox
Every peer maintains its own inbox and output. Messages received appear in order on the inbox, and messages to-be-sent are placed in order on the outbox.
Messages arrive in the inbox as commands are proposed into the ZooKeeper log. Technically, the inbox need only be size 1 since all log entries are processed strictly in order. As an optimization, the peer can choose to read a few extra commands behind the one it’s currently processing. In practice, the inbox will probably be configured with a size greater than one.
The outbox is used to send commands to the log. Certain commands processed by the peer will generate other commands. For example, if a peer is idle and it receives a command notifying it about a new job, the peer will react by sending a command to the log requesting that it be allocated for work. Each peer can choose to pause or resume the sending of its outbox messages. This is useful when the peer is just acquiring membership to the cluster. It will have to play log commands to join the cluster fully, but it cannot volunteer to be allocated for work since it’s not officially yet a member of the cluster.
Applying Log Entries
This section describes how log entries are applied to the peer’s local
replica. A log entry is a persistent, sequential znode. Its content is a
map with keys :fn and :args. :fn is mapped to a keyword that finds
this log entry’s implementation. :args is mapped to another map with
any data needed to apply the log entry to the replica.
Peers begin with the empty state value, and local state. Local state maintains a mapping of things like the inbox and outbox - things that are specific to this peer, and presumably can’t be serialized as EDN.
Each peer starts a thread that listens for additions to the log. When
the log gets a new entry, the peer calls
onyx.extensions/apply-log-entry. This is a function that takes a log
entry and the replica, and returns a new replica with the log entry
applied to it. This is a value-to-value transformation.

A single peer begins with the empty replica ({}) and progressively
applies log entries to the replica, advancing its state from one
immutable value to the next.

A peer reads the first log entry and applies the function to its local replica, moving the replica into a state "as of" entry 0

Because application of functions from the log against the replica are deterministic and free of side effects, peers do not need to coordinate about the speed that each plays the log. Peers read the log on completely independent timelines
Peers effect change in the world by reacting to log entries. When a log
entry is applied, the peer calls onyx.extensions/replica-diff, passing
it the old and new replicas. The peer produces a value summarizing what
changed. This diff is used in subsequent sections to decide how to react
and what side-effects to carry out.
Next, the peer calls onyx.extensions/reactions on the old/new
replicas, the diff, and its local state. The peer can decide to submit
new entries back to the log as a reaction to the log entry it just saw.
It might react to "submit-job" with "volunteer-for-task", for instance.

After a peer reads a log entry and applies it to the log replica, it will (deterministically!) react by appending zero or more log entries to the tail of the log.
Finally, the peer can carry out side-effects by invoking
onyx.extensions/fire-side-effects!. This function will do things like
talking to ZooKeeper or writing to core.async channels. Isolating side
effects means that a subset of the test suite can operate on pure
functions alone. Each peer is tagged with a unique ID, and it looks for
this ID in changes to its replica. The ID acts very much like the object
orientated "this", in that it uses the ID to differentiate itself to
conditionally perform side effects across an otherwise uniformly
behaving distributed system.
Joining the Cluster
Aside from the log structure and any strictly data/storage centric znodes, ZooKeeper maintains another directory for pulses. Each peer registers exactly one ephemeral node in the pulses directory. The name of this znode is a UUID.
3-Phase Cluster Join Strategy
When a peer wishes to join the cluster, it must engage in a 3-phase protocol. Three phases are required because the peer that is joining needs to coordinate with another peer to change its ZooKeeper watch. I call this process "stitching" a peer into the cluster.
The technique needs peers to play by the following rules: - Every peer must be watched by another peer in ZooKeeper, unless there is exactly one peer in the cluster - in which case there are no watches. - When a peer joins the cluster, all peers must form a "ring" in terms of who-watches-who. This makes failure repair very easy because peers can transitively close any gaps in the ring after machine failure. - As a peer joining the cluster begins playing the log, it must buffer all reactive messages unless otherwise specified. The buffered messages are flushed after the peer has fully joined the cluster. This is because a peer could volunteer to perform work, but later abort its attempt to join the cluster, and therefore not be able to carry out any work. - A peer picks another peer to watch by determining a candidate list of peers it can stitch into. This candidate list is sorted by peer ID. The target peer is chosen by taking the message id modulo the number of peers in the sorted candidate list. The peer chosen can’t be random because all peers will play the message to select a peer to stitch with, and they must all determine the same peer. Hence, the message modulo piece is a sort of "random seed" trick.

At monotonic clock value t = 42, the replica has the above :pairs
key, indicates who watches whom. As nodes are added, they maintain a
ring formation so that every peer is watched by another.
The algorithm works as follows:
-
let S = the peer to stitch into the cluster
-
S sends a
prepare-join-clustercommand to the log, indicating its peer ID -
S plays the log forward
-
Eventually, all peers encounter
prepare-join-clustermessage that was sent by it -
if the cluster size is
0: -
S instantly becomes part of the cluster
-
S flushes its outbox of commands
-
if the cluster size (
n) is>= 1: -
let Q = this peer playing the log entry
-
let A = the set of all peers in the fully joined in the cluster
-
let X = the single peer paired with no one (case only when
n = 1) -
let P = set of all peers prepared to join the cluster
-
let D = set of all peers in A that are depended on by a peer in P
-
let V = sorted vector of
(set-difference (set-union A X) D)by peer ID -
if V is empty:
-
S sends an
abort-join-clustercommand to the log -
when S encounters
abort-join-cluster, it backs off and tries to join again later
-
-
let T = nth in V of
message-id mod (count V) -
let W = the peer that T watches
-
T adds a watch to S
-
T sends a
notify-join-clustercommand to the log, notifying S that it is watched, adding S to P -
when S encounters
notify-join-cluster:-
it adds a watch to W
-
it sends a
accept-join-clustercommand, removing S from P, adding S to A
-
-
when
accept-join-clusterhas been encountered, this peer is part of the cluster -
S flushes its outbox of commands
-
T drops its watch from W - it is now redundant, as S is watching W

Peers 1 - 4 form a ring. Peer 5 wants to join. Continued below…

Peer 5 initiates the first phase of the join protocol. Peer 1 prepares to accept Peer 5 into the ring by adding a watch to it. Continued below…

Peer 5 initiates the second phase of the join protocol. Peer 5 notifies Peer 4 as a peer to watch. At this point, a stable "mini ring" has been stitched along the outside of the cluster. We note that the link between Peer 1 and 4 is extraneous. Continued below…

Peer 5 has been fully stitched into the cluster, and the ring is intact
Dead peer removal
Peers will fail, or be shut down purposefully. Onyx needs to: - detect the downed peer - inform all peers that this peer is no longer executing its task - inform all peers that this peer is no longer part of the cluster
Peer Failure Detection Strategy
In a cluster of > 1 peer, when a peer dies another peer will have a watch registered on its znode to detect the ephemeral disconnect. When a peer fails (peer F), the peer watching the failed peer (peer W) needs to inform the cluster about the failure, and go watch the node that the failed node was watching (peer Z). The joining strategy that has been outlined forces peers to form a ring. A ring structure has an advantage because there is no coordination or contention as to who must now watch peer Z for failure. Peer W is responsible for watching Z, because W was watching F, and F was watching Z. Therefore, W transitively closes the ring, and W watches Z. All replicas can deterministically compute this answer without conferring with each other.

The nodes form a typical ring pattern. Peer 5 dies, and its connection with ZooKeeper is severed. Peer 1 reacts by reporting Peer 5’s death to the log. Continued below…

At t = 45, all of the replicas realize that Peer 5 is dead, and that Peer 1 is responsible for closing the gap by now watching Peer 4 to maintain the ring.

One edge case of this design is the simultaneous death of two or more consecutive peers in the ring. Suppose Peers 4 and 5 die at the exact same time. Peer 1 will signal Peer 5’s death, but Peer 5 never got the chance to signal Peer 4’s death. Continued below…

Peer 1 signals Peer 5’s death, and closes to the ring by adding a watch to Peer 4. Peer 4 is dead, but no one yet knows that. We circumvent this problem by first determining whether a peer is dead or not before adding a watch to it. If it’s dead, as is Peer 4 in this case, we report it and further close the ring. Continued below…

Peer 1 signals peer 4’s death, and further closes to the ring by adding a watch to Peer 3. The ring is now fully intact.
Peer Failure Detection Thread
There is a window of time (inbetween when a peer prepares to join the cluster and when its monitoring peer notifies the cluster of its presence) that the monitoring node may fail, effectively deadlocking the new peer. This can occur because a peer will check if its monitoring dead is dead during the prepare phase - essentially performing eviction on a totally dead cluster - and may find a false positive that a node is alive when it is actually dead. The root issue is that ephemeral znodes stick around for a short period of time after the creating process goes down. The new peer must watch its monitor until it delivers the second phase message for joining - notification. When this occurs, we can stop monitoring, because the monitoring node is clearly alive. If the znode is deleted because the process exited, we can safely effect it and free the peer from deadlocking. Issue 416 found this bug, and offers more context about the specific problem that we encountered.
Garbage collection
One of the primary obstacles that this design imposes is the requirement of seemingly infinite storage. Log entries are only ever appended - never mutated. If left running long enough, ZooKeeper will run out of space. Similarly, if enough jobs are submitted and either completed or killed, the in memory replica that each peer houses will grow too large. Onyx requires a garbage collector to be periodically invoked.
When the garbage collector is invoked, two things will happen. The caller of gc will place an entry onto the log. As each peer processed this log entry, it carries out a deterministic, pure function to shrink the replica. The second thing will occur when each peer invokes the side effects for this log entry. The caller will have specified a unique ID such that it is the only one that is allowed to trim the log. The caller will take the current replica (log entry N to this log entry), and store it in an "origin" znode. Anytime that a peer boots up, it first reads out of the origin location. Finally, the caller deletes log entry N to this log entry minus 1. This has the dual effect of making new peers start up faster, as they have less of the log to play. They begin in a "hot" state.
The garbage collector can be invoked by the public API function
onyx.api/gc. Upon returning, the log will be trimmed, and the in
memory replicas will be compressed.

A peer can start by reading out of the origin, and continue directly to a particular log location.
Command Reference
-
Submitter: peer (P) that wants to join the cluster
-
Purpose: determines which peer (Q) that will watch P. If P is the only peer, it instantly fully joins the cluster
-
Arguments: P’s ID
-
Replica update: assoc
{Q P}to:preparekey. If P is the only peer, P is immediately added to the:peerskey, and no further reactions are taken -
Side effects: Q adds a ZooKeeper watch to P’s pulse node
-
Reactions: Q sends
notify-join-clusterto the log, with args P and R (R being the peer Q watches currently)
-
Submitter: peer Q helping to stitch peer P into the cluster
-
Purpose: Adds a watch from P to R, where R is the node watched by Q
-
Arguments: P and R’s ids
-
Replica update: assoc
{Q P}to:acceptkey, dissoc{Q P}from:preparekey -
Side effects: P adds a ZooKeeper watch to R’s pulse node
-
Reactions: P sends
accept-join-clusterto the log, with args P, Q, and R
-
Submitter: peer P wants to join the cluster
-
Purpose: confirms that P can safely join, Q can drop its watch from R, since P now watches R, and Q watches P
-
Arguments: P, Q, and R’s ids
-
Replica update: dissoc
{Q P}from:acceptkey, merge{Q P}and{P R}into:pairskey, conj P onto the:peerskey -
Side effects: Q drops its ZooKeeper watch from R
-
Reactions: peer P flushes its outbox of messages
-
Submitter: virtual peer P wants to become active in the cluster
-
Purpose: P affirms that it’s peer group has been safely stitched into the cluster
-
Arguments: P’s id
-
Replica update: conj P into
:peers, remove from:orphaned-peers -
Side effects: All virtual peers configure their workload and possibly start new tasks
-
Reactions: none
-
Submitter: peer (Q) determines that peer (P) cannot join the cluster (P may = Q)
-
Purpose: Aborts P’s attempt at joining the cluster, erases attempt from replica
-
Arguments: P’s id
-
Replica update: Remove any
:preparedor:acceptedentries where P is a key’s value -
Side effects: P optionally backs off for a period
-
Reactions: P optionally sends
:prepare-join-clusterto the log and tries again
-
Submitter: peer (Q) reporting that peer P is dead
-
Purpose: removes P from
:prepared,:accepted,:pairs, and/or:peers, transitions Q’s watch to R (the node P watches) and transitively closes the ring -
Arguments: peer ID of P
-
Replica update: assoc
{Q R}into the:pairskey, dissoc{P R} -
Side effects: Q adds a ZooKeeper watch to R’s pulse node
-
Submitter: virtual peer P is leaving the cluster
-
Purpose: removes P from its task and consideration of any future tasks
-
Arguments: peer ID of P
-
Replica update: removes P from
:peers -
Side effects: All virtual peers reconfigure their workloads for possibly new tasks
-
Submitter: peer (P), who has seen the leader sentinel
-
Purpose: P wants to propagate the sentinel to all downstream tasks
-
Arguments: P’s ID (
:id), the job ID (:job), and the task ID (:task) -
Replica update: If this peer is allowed to seal, updates
:sealing-taskwith the task ID associated this peers ID. -
Side effects: Puts the sentinel value onto the queue
-
Reactions: None
-
Submitter: Client, via public facing API
-
Purpose: Send a catalog and workflow to be scheduled for execution by the cluster
-
Arguments: The job ID (
:id), the task scheduler for this job (:task-scheduler), a topologically sorted sequence of tasks (:tasks), the catalog (:catalog), and the saturation level for this job (:saturation). Saturation denotes the number of peers this job can use, at most. This is typically Infinity, unless all catalog entries set:onyx/max-peersto an integer value. Saturation is then the sum of those numbers, since it creates an upper bound on the total number of peers that can be allocated to this task. -
Replica update:
-
Side effects: None
-
Reactions: If the job scheduler dictates that this peer should be reallocated to this job or another job, sends
:volunteer-for-taskto the log
-
Submitter: Client, via public facing API
-
Purpose: Stop all peers currently working on this job, and never allow this job’s tasks to be scheduled for execution again
-
Arguments: The job ID (
:job) -
Replica update: Adds this job id to
:killed-jobsvector, removes any peers in:allocationsfor this job’s tasks. Switches the:peer-statefor all peer’s executing a task for this job to:idle. -
Side effects: If this peer is executing a task for this job, stops the current task lifecycle
-
Reactions: If this peer is executing a task for this job, reacts with
:volunteer-for-task
-
Submitter: Client, via public facing API
-
Purpose: Compress all peer local replicas and trim old log entries in ZooKeeper.
-
Arguments: The caller ID (
:id) -
Replica update: Clears out all data in all keys about completed and killed jobs - as if they never existed.
-
Side effects: Deletes all log entries before this command’s entry, creates a compressed replica at a special origin log location, and updates to the pointer to the origin
-
Reactions: None
-
Submitter: peer (P), who has successfully started its incoming buffer
-
Purpose: Indicates that this peer is ready to receive segments as input
-
Replica update: Updates
:peer-stateunder the:idof this peer to set its state to:active. -
Side effects: If this task should immediately be sealed, seals this task
-
Reactions: None.
-
Submitter: This is a special entry that should never be appended to the log
-
Purpose: Perform a hard reset of the replica, replacing its entire value. This is useful if a log subscriber is reading behind a garbage collection call and tries to read a non-existent entry. The new origin can be found and its value applied locally via the subscriber.
-
Replica update: Replaces the entire value of the replica with a new value
-
Side effects: None.
-
Reactions: None.
Can you improve this documentation? These fine people already did:
Lucas Bradstreet, vijaykiran & 胡雨軒 ПетрEdit on GitHub
cljdoc builds & hosts documentation for Clojure/Script libraries
Keyboard shortcuts
× close| Ctrl+k | Jump to recent docs |
| ← | Move to previous article |
| → | Move to next article |
| Ctrl+/ | Jump to the search field |